
Ph.D.
Researcher
Kyoto University, School of Informatics
Department of Intelligence Science and Technology
Speech and Audio Processing Lab.
E-mail: lisheng[at]sap.ist.i.kyoto-u.ac.jp
RESEARCH FOCUS:
-
Acoustic modeling for LVCSR systems (English, Chinese, Japanese)
familiar with Cambridge GALE Mandarin system, CAS Acoustic Institution Mandarin system, Kyoto University Japanese CSJ system, NICT English spoken lecture system
-
ASR result confidence estimation and correction.
-
Lightly-supervised/semi-supervised/ensemble acoustic model training (spoken lectures).
-
Acoustic model and language model adaptation (spoken lectures).
EDUCATION:
-
2006.7 B.S Computer Science,
Nanjing University
-
2009.7 M.E Software and Embedded Systems,
Nanjing University(Joint Program of Chinese Academy of Sciences, Chinese University of Hong Kong and Nanjing University)
-
2016.3 Ph.D Informatic Science,
Kyoto University (supported by Japanese Government)
PUBLICATIONS:
GoogleScholar | ResearchGate
Ph.D Thesis:
-
Sheng Li (supervised by Prof. Tatsuya Kawahara).
Speech Recognition Enhanced by Lightly-supervised and Semi-supervised Acoustic Model Training.
Ph.D. Thesis, Kyoto University, Feb, 2016.
Journals:
-
S.Li, Y.Akita, and T.Kawahara.
Semi-supervised acoustic model training by discriminative data selection from multiple ASR systems' hypotheses.
IEEE Trans. Audio, Speech \& Language Process., Vol.24, No.9, pp.1520--1530, 2016.
(text) (PDF)
-
S.Li, Y.Akita, and T.Kawahara.
Automatic lecture transcription based on discriminative data selection for lightly supervised acoustic model training.
IEICE Trans., Vol.E98-D, No.8, pp.1545--1552, 2015.
(text) (PDF)
-
L. Wang, H. Chen, S. Li and H. Meng.
Phoneme-level articulatory animation in pronunciation training,
Speech Communication, Vol. 54, Issue 7, Sept. pp. 845–856, 2012.
(text) (PDF)
International Conferences:
-
S.Li, X.Lu, S.Sakai, M.Mimura and T.Kawahara
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
Accepted in IEEE-ICASSP, 2017.
-
S.Li, X.Lu, S.Mori, Y.Akita, T.Kawahara.
Confidence Estimation for Speech Recognition Systems using Conditional Random Fields Trained with Partially Annotated Data
Int'l Sympo. Chinese Spoken Language Processing (ISCSLP), 2016.
(PDF)
-
S.Li, Y.Akita, and T.Kawahara.
Data selection from multiple ASR systems' hypotheses for
unsupervised acoustic model training.
In Proc. IEEE-ICASSP, pp.5875--5879, 2016.
(text) (PDF)
-
S.Li, Y.Akita, and T.Kawahara.
Discriminative data selection for lightly supervised training of
acoustic model using closed caption texts.
In Proc. INTERSPEECH, pp.3526--3530, 2015.(oral)
(text) (PDF)
-
S.Li, X.Lu, Y.Akita, and T.Kawahara.
Ensemble speaker modeling using speaker adaptive training deep neural
network for speaker adaptation.
In Proc. INTERSPEECH, pp.2892--2896, 2015.
(text) (PDF)
-
S.Li, Y.Akita, and T.Kawahara.
Corpus and transcription system of Chinese Lecture Room.
In Proc. Int'l Sympo. Chinese Spoken Language Processing
(ISCSLP), pp.442--445, 2014.
(text) (PDF)
-
S. Li and L. Wang.
Cross Linguistic Comparison of Mandarin and English EMA Articulatory Data,
In Proc. INTERSPEECH, 2012. (Travel granted by IBM research)
(text) (PDF)
-
S. Li, L. Wang and E. Qi.
The Phoneme-level Articulator Dynamics for Pronunciation Animation,
In Proc. IALP, Nov.15-17, Pages 283-286, 2011.
(text) (PDF)
-
J. Chen, L. Wang, C. Li, J. Hu and S. Li.
IELS: A Computer-aided Pronunciation Training System for Undergraduate Students,
ICETC, Vol.1, pp.338-342, 2010.
(text) (PDF)
Technical Reports:
-
S. Li, X. Lu, S. Sakai, T. Kawahara,
Diversity-driven Semi-supervised Ensemble DNN Acoustic Model Training,
ASJ autumn, 2016.
-
S. Li, X. Lu, S. Sakai, T. Kawahara,
Diversity-driven Semi-supervised Ensemble DNN Acoustic Model Training,
IPSJ IEICE-SP2016-40, 2016. (oral)
-
S. Li, Y. Akita, T. Kawahara,
Discriminative data selection from multiple ASR systems' hypotheses for unsupervised acoustic model training,
IPSJ SIG-SLP-109-8, 2015.(oral)
- S. Li, Y. Akita, T. Kawahara,
Effective combination of multiple ASR hypotheses with CRF-based classifiers,
ASJ autumn, 2015.
- S. Li, Y. Akita, T. Kawahara,
Incorporating divergences from hypotheses of multiple ASR systems to improve unsupervised acoustic model training,
ASJ spring, 2015.
- S. Li, Y. Akita, T. Kawahara,
Unsupervised Training of Deep Neural Network Acoustic Models for Lecture Transcriptions,
ASJ autumn, 2014.
- S. Li, Y. Akita, T. Kawahara,
Classifier-based data selection for lightly-supervised training of acoustic model for lecture transcription,
IPSJ SIG-SLP-102-4, 2014.(oral)
- S. Li, Y. Akita, T. Kawahara,
Data Selection Assisted by Caption to Improve Acoustic Modeling for Lecture Transcription,
ASJ spring, 2014.(oral)
-
S. Li, M. Mimura, T. Kawahara,
Automatic Transcription of Chinese Spoken Lectures,
ASJ autumn, 2013.
-
S. Li, K. Luo and L. Wang,
The Phoneme-level Articulator Dynamics for 3D Pronunciation Animation for Chinese,
Bulletin of Advanced Technology Research, Vol.5 No.10/Otc.2011, Pages 5-7.
-
S. Li and C. Li,
Application of the RFID based audio service in regional navigation system,
Bulletin of Advanced Technology Research, Vol.3 No.2/Feb.2009, Pages 44-47.
Research Projects:
1.Mis-pronunciation detection for second language learners (NSFC60772165)(2009-2012)
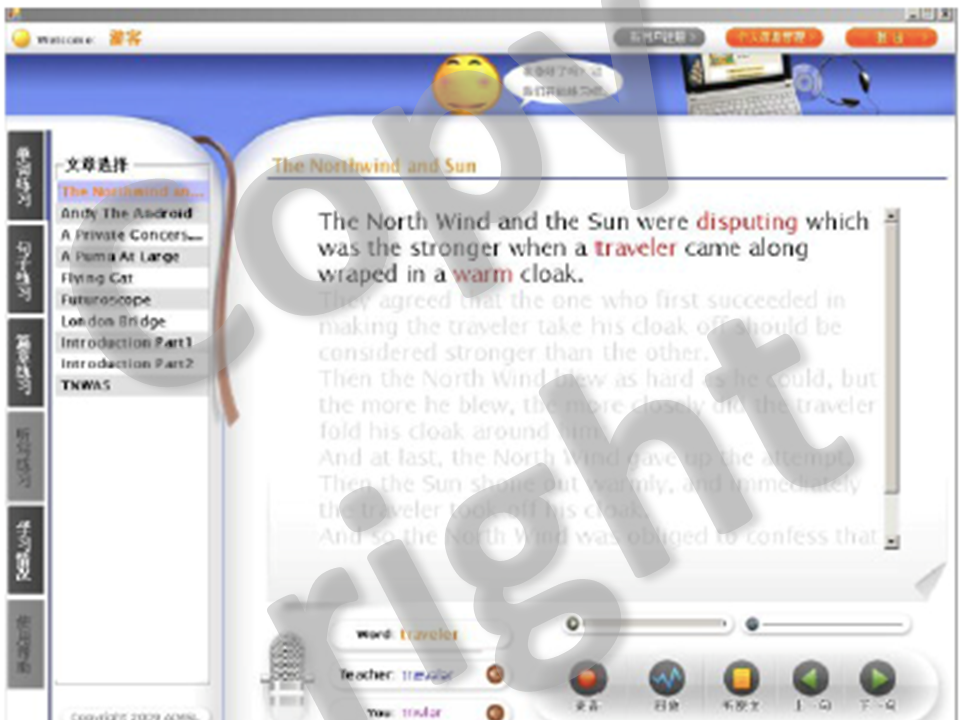
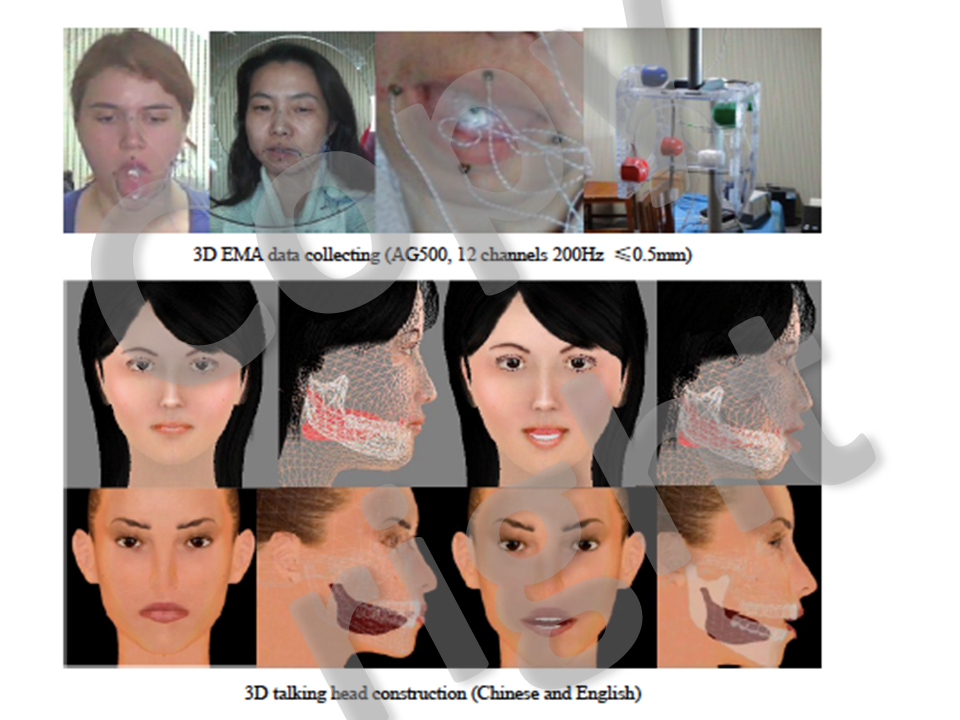
2.Phone-level articulatory 3D animation in pronunciation training (NSFC61135003)(2009-2012)
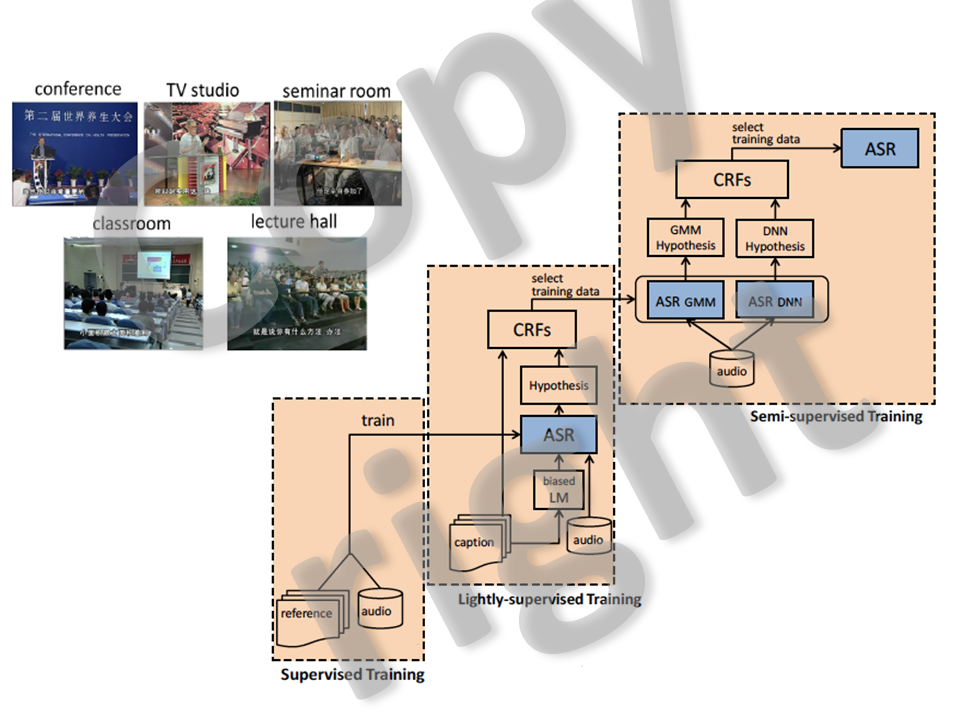
3.Spoken lecture transcription enhanced by lightly-supervised and semi-supervised training(2012-now)

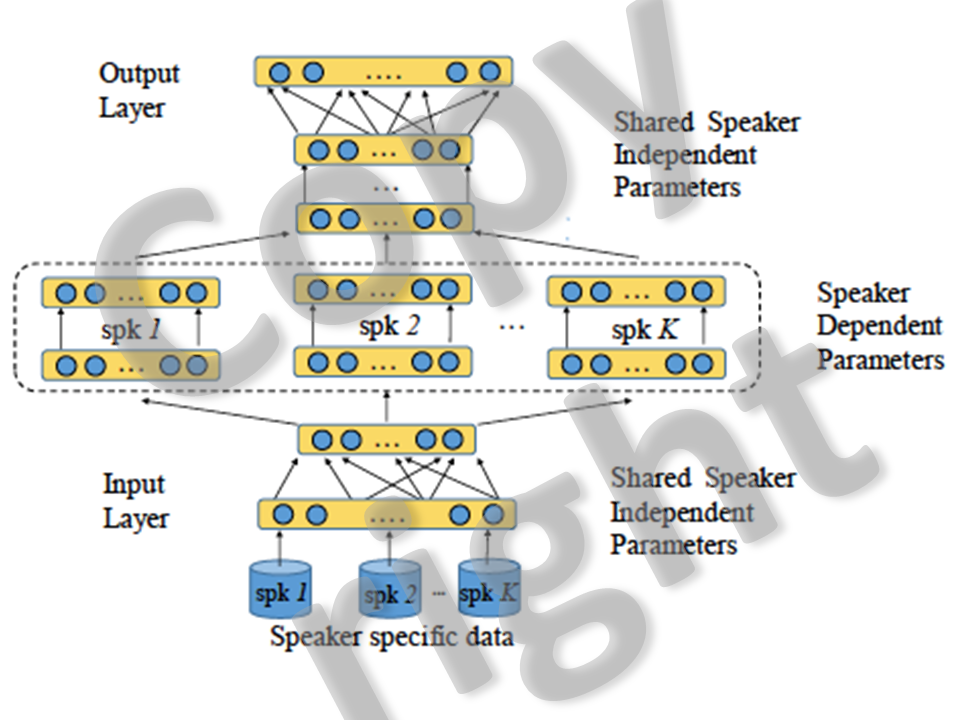
4.Research about speaker adaptive training of DNN acoustic model (cooperation with NICT)(2012-now)
5.ERATO project (2015-now)
English acoustic modeling for Erica (the robot),
Parallel DNN acoustic modeling for large corpus
Speaker adaptation
AWARDS:
[1] 2002 Award of chemistry and biology Olympic for high school students (Jiangsu Province)
[2] 2002 Chen Yinchuan Scholarship for Excellent University New Students
[3] 2004 People's Scholarship of Nanjing University
[4] 2011 Excellent Staff Award of Chinese Academy of Sciences
[5] 2011 Best Creative Project Award in Young Entrepreneur Program 2011, HK
[6] 2012 MEXT scholarship by Japanese Government
[7] 2012 Travel grant by IBM research for INTERSPEECH2012 at Portland
ACADEMIC SERVICES:
[1] Reviewer for NAACL-HLT 2016.
[2] Reviewer for Doctoral Consortium at Interspeech2015.
MEMBERSHIP:
IEEE-SPS (Signal Processing Society),
ISCA (International Speech Communication Association),
ASJ (Acoustical Society of Japan),
SIG-CSLP (Chinese Spoken Language Processing),
APSIPA (Asia Pacific Signal and Information Processing Association)
SOFTWARE & RECIPES:
coming soon...
DATA RELEASES:
coming soon...
ALUMNI:
Nanjing University
NJUer at Kansai
Lilybbs
Last update: 2016-8-20
